
¡Hola! Te doy la bienvenida a esta nueva edición de The Independent Sentinel, la newsletter para estar al día sobre todo lo que ocurre en el vibrante mundo de la Inteligencia Artificial.
Si deseas suscribirte para recibir cada edición en tu correo electrónico, puedes hacerlo fácilmente aquí:
Hoy hablamos de comunicación entre aplicaciones, de cosas que hablan y de una historia de traiciones.

¡Arrancamos! ⚡️
1. Tendencias 📈
🧩 Las Nuevas APIs
El concepto de API (Application Programming Interface) es uno de los más importantes en el mundo de la computación y las comunicaciones ya que, aún antes de la aparición de Internet, hemos venido usando esta idea para conseguir que los programas de software “hablasen” entre sí.
Explicado de forma muy sencilla, una API es el “contrato” de comunicación entre dos programas, un “cliente” y un “servidor” en el que se especifica principalmente:
-
Qué cosas puede pedir un cliente
-
Qué necesita proporcionar el cliente para cada petición
-
Los formatos de las respuestas que devuelve el servidor
-
Los posibles mensajes de error
Veamos un ejemplo sencillo con el siguiente proceso
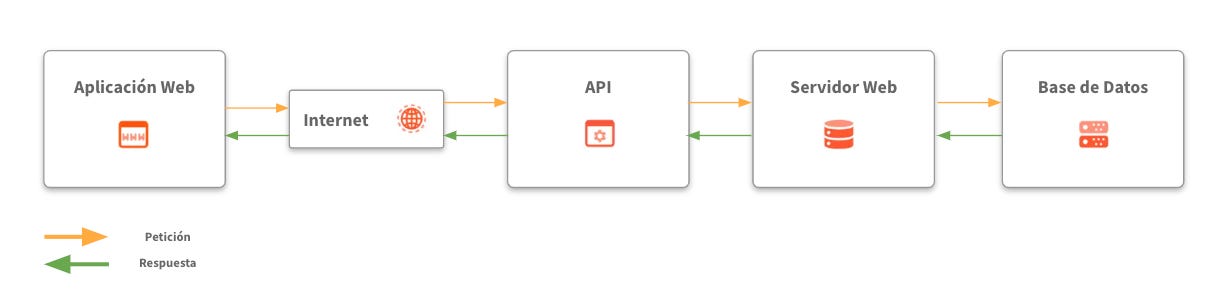
En el fondo, las APIs representan una herramienta para acceder de manera ordenada a datos remotos que permite que un software pueda comunicarse con otro software.
Es aquí dónde la cosa se pone interesante, ya que si dotásemos a los modelos de lenguaje de capacidad para usar esta herramienta, podrían acceder a todo tipo de información y hacer uso de todo tipo de servicios online, otorgándoles una versatilidad infinita para llevar a cabo todo tipo de tareas.
Siguiendo con este razonamiento, un LLM con capacidad de comunicación con APIs, sería un ejemplo perfecto del concepto de Agente de IA ya que sus capacidades ejecutivas serían ilimitadas al ser las APIs el estándar de comunicación entre softwares en el mundo actual.
¿Cómo podemos ayudar a los modelos de lenguaje a usar APIs? El problema principal es que hay una tremenda cantidad de APIs distintas, con distintas especificaciones y distintos mods de funcionamiento. Tan es así que cada fuente de datos con al que queramos conectar vía API desde un LLM requieres hacer una implementación ad-hoc.
Para combatir este problema de homogeneización, desde Anthropic han estado trabajando en un nuevo protocolo para facilitar la comunicación entre las APIs y los modelos de lenguaje. Su nombre es MCP (Model Context Protocol) y esto es en lo que consiste.

Tal y como explica Anthropic, podemos pensar en MCP como un puerto USB-C para aplicaciones de IA, esto es, un conector “universal” que permita a un modelo conectarse a todo tipo de aplicaciones sin necesidad de conocer de manera detallada los detalles de la API subyacente que define la comunicación.

MCP propone un protocolo único y universal para estas integraciones haciendo que los sistemas de IA puedan acceder de manera más sencilla a la información que necesitan.
Usando una arquitectura cliente-servidor clásica, MCP permite consumir servicios e información tanto de fuentes de datos locales como remotas usando servidores MCP que abstraen la complejidad de la integración.
Es más, si usas alguna de las herramientas de “vibe-coding” de las que hemos visto en las últimas ediciones como Cursor o Windsurf, ya se viene usando MCP para conectar estos IDEs con GitHub o con bases de datos entre muchas otras cosas.
Un hecho muy relevante es que ya existen repositorios de MCP en los que se puede acceder a servidores par aplicaciones tan conocidas como Google Drive, Git o Slack. Puedes ver uno de ellos aquí (¡hay muchísimos servidores disponibles!).
¿Significa esto que MCP va a sustituir a las APIs? Realmente no, ya que son capas distintas. De hecho, MCP sigue usando las APIs. Por ejemplo, el servidor MCP de Google Drive sigue usando la API oficial de Google “por debajo” para hacer que todo funcione.
MCP no sustituye a las APIs, sino que las “estandariza” a los ojos de la IA, haciendo que sea más fácil conectar modelos y herramientas.
Para aquellos más técnicos, he preparado una tabla con las diferencias entre las APIs y MCP para entender mejor las diferencias:
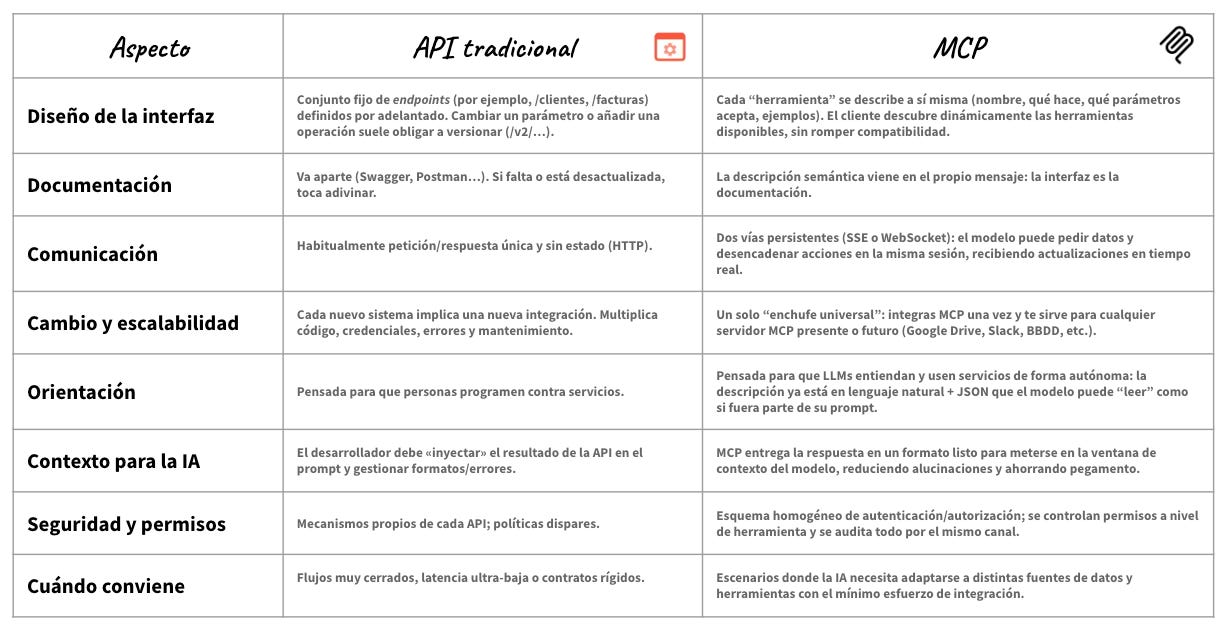
Y sí, puede que acaben surgiendo más alternativas a MCP pero, por ahora, parece que se está asentando como el estándar de facto. Baste como ejemplo que, hace apenas unos días, hasta OpenAI ha anunciado el soporte para esta tecnología:
MCP supone un avance significativo en la integración de la IA con el mundo real. Hacer que sea más fácil usar herramientas para los modelos es sin duda el mejor camino para construir agentes de IA cada vez más potentes y versátiles.
🕰️ El Internet de las Cosas (Inteligentes)
La historia reciente de la tecnología viene marcada por ciclos continuos de expectativas y decepciones siguiendo de manera muy precisa el conocidísimo modelo de Gartner acerca del llamado “Hype Cycle” o “Ciclo de sobreexpectación” (qué mal nombre) en español.

El ciclo Gartner consta de 5 fases que representan las expectativas tras la aparición de una nueva tecnología. Estas son las 5 fases:
-
Technology trigger (Disparador de la innovación): Primera aparición de una tecnología, ya sea un prototipo inicial, un hallazgo de I+D o una publicación científica al respecto.
-
Peak of Inflated Expectations (Pico de expectativas sobredimensionadas): Los medios y “visionarios” proclaman que, esta sí, será la tecnología que cambie el mundo. Se exageran capacidades, plazos y, sobre todo, impacto.
-
Trough of Disillusionment (Valle de la desilusión): El choque con la realidad. Las limitaciones técnicas, la regulación, los costes, la falta de retorno o las dificultades operativas ponen en duda la factibilidad/viabilidad de las iniciativas relacionadas con esta tecnología.
-
Slope of Enlightenment (Rampa de “iluminación”): Los actores que sobreviven el paso por el valle de la desilusión refinan la tecnología, la mejoran, la acercan a los casos de uso reales y aparecen buenas prácticas, métricas y normas para su uso.
-
Plateau of Productivity (Meseta de productividad): Por fin la tecnología se entiende, estandariza y adopta de forma sostenible. El retorno en estas inversiones es ya claro y medible.
Para el caso de IoT (el “Internet de las Cosas”), en 2020 y después de pasar el “hype” se encuentra en su “camino en el desierto” hacia la meseta de la productividad, un proceso siempre más lento de lo esperado ya que, aún en 2025, parece de algún modo que seguimos ahí.

En cualquier caso, y como hemos visto en numerosísimas ediciones de esta newsletter, todo esto de la tecnología y la innovación no va de cómo empiezan las cosas, sino de como acaban. Y lo cierto es que, como en tantos otros ámbitos, la IA puede jugar un papel relevante en el desarrollo y quién sabe si transformación de este concepto tecnológico que es el Internet de las Cosas.
Hace unos meses, mi muy admirado Andrej Karpathy hacía mención de soslayo en una entrevista a un concepto interesantísimo: El Internet de las Cosas Inteligentes.
Y lo hacía con un ejemplo muy gráfico y entendible: las películas Disney. Si recuerdas, en la película de la Bella y La Bestia, hay varios personajes que son “objetos”, pero objetos con inteligencia humana (más que nada porque son humanos transformados).

En el vídeo, que merece la pena ver, Andrej Karpathy asevera que nos estamos moviendo a un mundo en el que todos los objetos “estarán vivos” como en una de estas películas animadas y que interactuaremos con ellos de manera tan natural como lo hacemos con otras personas.
¿Será esto el empujón que necesitaban los sistemas IoT para su implantación en los hogares? No estoy seguro, de lo que si estoy seguro es que más pronto que tarde empezaremos a encariñarnos de estos objetos cotidianos con los que, a partir de ahora, no pararemos de relacionarnos.
2. Historias 📔
🎼 ¿Quieres banda sonora? ¡Dale al Play!
💡 La búsqueda del transistor
La leyenda de Silicon Valley tiene su origen en que, entre los años 50 y 70, esta región californiana se llenó de fabricantes de circuitos integrados y chips. Estas empresas de semiconductores eras los primeros representante de una industria emergente que acabaría cambiando el mundo.
Todo empezó -oh sorpresa- en los Laboratorios Bell (sí, sé que tengo pendiente un monográfico sobre esto) cuando un joven ingeniero llamado William Bradford Shockley se unió a un grupo de investigación de la compañía dedicado a desarrollar los transistores de estado sólido como reemplazo a los tradicionales tubos de vacío que se usaban hasta el momento en toda la red telefónica de Bell.
Shockley empezó a trabajar en posibles diseños y llegó a armar un primer prototipo fallido en 1939 cuando, por la llegada de la guerra, tuvo que abandonar durante varios años esta investigación para dedicarse a asuntos de defensa anti-submarinos y nuevos radares (entre muchas otra cosas) en colaboración con el Pentágono y altos mandos militares.

En 1945, tras acabar la guerra, Shockley retomó su actividad en Bell y comenzó a liderar un grupo de investigación de física del estado sólido que acabó dando con el concepto de efecto de campo que daría nombre a un conocido tipo de transistores.
Sin embargo, y por asuntos legales, el nombre de Shockley no apareció en las diversas patentes que se lanzaron desde los laboratorios Bell, hecho que le irritó profundamente.
Pese a ello, nuestro protagonista siguió trabajando, ya por su cuenta, en nuevos tipos de transistores y tuvo tiempo de publicar una obra de 558 páginas, su obra magna, llamada “Electrons and Holes in Semiconductors with Applications to Transistor Electronics”

Las investigaciones y la labor divulgativa de Shockley acabó desembocando en la invención del transistor de unión bipolar (Bipolar Junction Transistor), lo que llevo a Shockley a ser considerado como el inventor del transistor junto con sus predecesores John Barden y Walter Brattain que descubrieron el transistor de contacto puntual. Este hecho llevó a los 3 a ser condecorados con el Premio Nobel de Física en 1956.

👣 La primera startup de Silicon Valley
El mismo año en el que recibió el premio Nobel, Shockley dejó los laboratorios Bell para fundar su propia empresa: Shockley Semiconductor Laboratory en Mountain View (California), muy cerca de la casa de su madre y en colaboración con u compañero Arnold Beckman.
Shockley Semiconductor Laboratory se puede considerar como la primera empresa de semiconductores en la zona que acabaría llamándose Silicon Valley como todos conocemos.
Shockley alquiló un pequeño edificio y empezó a contratar a su equipo para comenzar a desarrollar con premura semiconductores.

Shockley pudo reclutar a ingenieros de gran talento y la compañía empezó a conseguir resultados. Lamentablemente, no todo iban a ser buenas noticias para Shockley.
🔪 Los 8 traidores
Piensa por un momento en el jefe más complicado con el que te haya tocado trabajar. Ahora multiplícalo por diez y tendrás, según se decía, a un jefe como Shockley.
Aparentemente, Shockley no era el mejor gestor de personas del mundo, su manera de trabajar y su obsesión con la construcción de diodos de cuatro capas p-n-p-n que le acompañaba desde que trabajaba en Bell, estaba impidiendo a la compañía poder progresar con oportunidades de negocio más verosímiles.
Muchos de los empleados de la compañía pidieron al cofundador, Beckman, que hubiese un cambio en la gerencia, pero las peticiones fueron desoídas y, finalmente, ocho de los empleados más brillantes -entre los que se encontraban unos tales Moore y Noyce- renunciaron a sus puestos de trabajo decididos a crear una nueva empresa. Estos ocho hombres fueron llamados los ocho traidores.

Esta nueva aventura necesitaba de financiación y dado que no era una empresa al uso, no era tan fácil recurrir a los inversores habituales. Hacía falta alguien con la suficiente visión y con la suficiente poca aversión al riesgo para poner sus dólares en una aventura de estas características.
Ese banquero con los bolsillos lo suficientemente profundos era Arthur Rock que, tras su a la postre exitosa inversión en este compañía, acabaría fundando uno de los primeros fondos de Capital Riesgo en la costa Oeste norteamericana. La financiación fue de 1.38 millones de dólares y llego en el momento justo.
El acuerdo se firmó en un billete que ha pasado a los anales de la historia del Capital Riesgo el 19 de Septiembre de 1957.

La urgencia nacional de recuperar el liderazgo tecnológico frente a la Unión Soviética hizo que la necesidad de estos dispositivos electrónicos para los sectores de la defensa y el espacio se disparase en la época. La recién creada compañía empezó a satisfacer esta creciente demanda mediante un nuevo transistor fabricado en silicio.

En apenas unos meses, sus oficinas se les quedaron pequeñas y abrieron un centro I+D (también en Palo Alto) para continuar con la investigación y seguir creando nuevos productos en un mercado en continuo crecimiento.

Uno de los ocho fundadores, Robert Noyce, concibió una idea: depositar aluminio sobre una capa de vidrio para interconectar selectivamente los transistores, resistencias y otros componentes en la oblea de silicio subyacente.
Esta idea fue el origen del primer circuito integrado. Constaba únicamente de 4 transistores y cinco resistencias. Era 1961 y la revolución del silicio estaba a punto de comenzar.

Cabe destacar que la NASA escogió los chips de esta compañía para la computadora de control de las misiones Apolo y que, en aquella época, se convirtió en el principal comprador de este tipo de artefactos.
Además de ser pioneros en la fabricación de circuitos, entre los fundadores se encontraba el ahora célebre Gordon Moore, que enunció 1965 la ley que lleva su nombre y que, aún con matices, se ha venido cumpliendo de manera más o menos precisa.
La Ley de Moore indicaba que, cada 2 años, sería posible duplicar el número de transistores en un microprocesador. Sea esto una precisa clarividencia sobre el futuro o una profecía autocumplida -cosa más probable- lo cierto es que ha sido una buenísima noticia que esta teoría se haya venido haciendo realidad.
Me acabo de dar cuenta de que aún no he mencionado el nombre de esta empresa. Tal vez te suene: Fairchild Semiconductor Corporation.
👤 La alargada sombra de Fairchild
Fairchild fue el origen del Silicon Valley que conocemos hoy y, curiosamente, muchas de las grandes compañías de semiconductores tienen sus orígenes en Fairchild.

No solo eso, muchas de las grandes tecnológicas actuales hunden sus raíces en Fairchild, convirtiendo a esta compañía en el origen de la industria tecnológica moderna. A todas las empresas descendientes de Fairchild se las denomina, con acierto, como Fairchildren.

De entre todas ellas vamos a centrarnos en una. Y es que en 1960, todo se complicó para Fairchild.
🌸 Una tarde de primavera de 1960
Esa tarde, Gordon Moore se pasó por la casa de Bob Noyce ya que venía barruntando algo en su cabeza desde hacía un tiempo. La idea era que los dispositivos de memoria construidos con circuitos integrados podrían ser ideales para sustituir a las memorias magnéticas de la época. Y no solo eso, esta idea podría tener sentido incluso para crear una nueva compañía fuera de Fairchild.
 and Gordon Moore")
Poco después, ya en verano, Moore y Noyce se decidieron a avanzar en esa nueva aventura empresarial. Al poco tiempo Andy Grove también se unió al grupo. La noticia sacudió Silicon Valley ya que dos de los famosos ocho traidores, volvieron a “traicionar” (si es que se puede llamar así) para crear su propia empresa.

¿El nombre final de esta compañía? Este seguro que te va a sonar: Intel Corporation, una abreviación de INTegrated ELectronics. El financiador de esta aventura fue de nuevo Arthur Rock, que les ayudo a “levantar” los 2.5 millones que les hacían falta. Reseñar que este mismo Rock fue de los primeros inversores de Apple. Difícil hacerlo mejor en el Capital Riesgo que este señor.

Inicialmente, el foco de Intel no estaba en los microprocesadores sino en la memoria de semiconductores. En 1969 lanzaron la SRAM 3101 y un año después la DRAM 1103 que supuso su primer éxito comercial al convertirse en la primera memoria dinámica de acceso aleatorio del mercado.

Poco después, Gordon y Noyce abrieron el camino del microprocesador y, en 1971, crearon el primer microprocesador comercial de la historia, el Intel 4004.

La carrera de la computación había dado el pistoletazo de salida.
⌨️ El mundo del x86
Los microprocesadores de Intel siguieron progresando en potencia y sofisticación y ya en 1978 lanzó el conocidísimo chip Intel 8086. Lo más especial de este procesador es que el era el primero de 16 bits y acabó dando nombre a la “familia” de procesadores x86. En paralelo, Intel lanzó una versión más barata paro compatible denominada con 8088 que, aunque menos conocido, acabó sellando el destino de la arquitectura x86.
EL 8088 fue el chip escogido por IBM para su primer PC en 1981, año en el que, casualmente o no, yo nací.

En España, este procesador y sus sucesores se fueron comercializando algunos años más tarde. Recuerdo con nostalgia aquellos años de evolución en los procesadores, no ya tanto por la parte tecnológica sino por los juegos a los que nos daban acceso. Quién por aquellos entonces tenía un 486, tenia en sus manos la auténtica bestia de la computación.
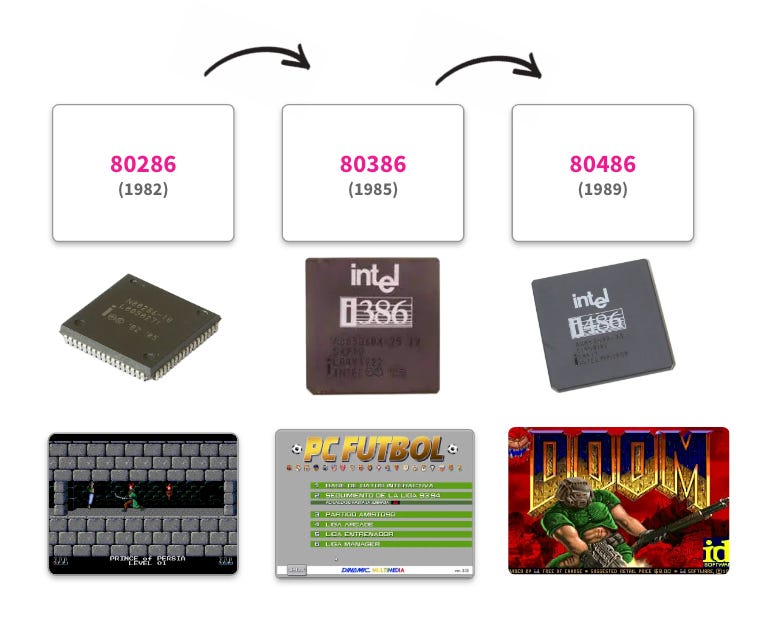
Intel quería continuar la exitosa familia de los x86 y decidió proteger de manera comercial los nombres de sus procesadores ya que aún no habían sido registrados. La sorpresa fue que, al intentar registrar el nuevo procesador 80586 en 1993, descubrieron que era imposible crear nombres comerciales usando solo números. Hacía falta un nuevo nombre.
📝 Un cambio de nombre
Pentium fue el primer procesador que no se nombró usando un número. El 586 que todos esperábamos vino con un nombre aún más atractivo que tenía el 5 (Penta) en su raíz.

A partir de 1993, Intel comenzó una encarnizada batalla comercial con AMD que en mi opinión ganó. Pentium fue garantía durante años de potencia y vanguardia y sus posteriores evoluciones fueron líderes de mercado.
No fue hasta 2006 cuando se abandonó la nomenclatura para chips de vanguardia y Pentium quedó relegada como marca a la gama más básica de procesadores de Intel. Actualmente, los procesadores Pentium se encuentran por encima de los Intel Celeron y por debajo de los Core i3. Tal vez no es el final que merecía un chip tan emblemático como este.
😵💫 Posibilidades desaprovechadas
Supongo que, como siempre, te estarás preguntando qué tiene que ver todo esto con la Inteligencia Artificial. El caso es que, más allá de la interesantísima historia del origen de los chips modernos, de esta evolución se desprenden algunas preguntas relevantes.
¿Fuimos capaces en su momento de aprovechar toda la potencia de estos chips?
La respuesta es que probablemente no. Hace poco leí con entusiasmo un experimento en el que los unos hackers (en el mejor sentido de la palabra) lograron algo que se nos podría antojar imposible: Ejecutar un modelo Llama en un procesador Pentium II con Windows 98. Si, lo estás leyendo bien, en un Pentium II.
El primer paso fue comprar un viejo Pentium II en eBay:

El segundo reto fue encontrar un ratón y un teclado compatibles ya que, por aquel entonces, aún no existían los conectores USB.
Usando el protocolo FTP transfirieron a esta máquina los pesos del modelo, el tokenizador y el código para realizar la inferencia.
El problema principal venía ahora. ¿Cómo compilar el código de inferencia para ejecutarlo en este equipo tan antiguo? Aquí es dónde nuestro buen Karpathy (del que hemos hablado en la primera sección de esta edición) vuelve a entrar en juego.
Hace tiempo, Karpathy hizo una implementación de un modelo en inferencia con fines didácticos en puro lenguaje C en apenas 700 líneas de código. Basados en este código, el equipo EXO hizo algunos cambio adicionales requeridos para la compilación e, igualmente, liberaron el código en el repositorio llama98.c.
Y, mágicamente, funcionó:

Nada más y nada menos que un modelo Llama de 260k parámetros corriendo en esta CPU sin, obviamente, GPU a una velocidad de 39 tokens por segundo.
Este experimento, que puedes ver completo aquí apunta a que la optimización en tamaño y prestaciones de los modelos de lenguaje y otros modelos generativos acabará haciendo que el coste del uso sea tan, tan bajo que se convierta en una commodity.
El acceso a inteligencia sintética será constante y ubicuo y, como bien dicen los autores de este experimento:
If it runs on 25-year-old hardware, then it runs anywhere.
Como comentaba Marc Andreessen, el famoso inversor, en una entrevista reciente:
“Podríamos haber estado hablando a las maquinas en lenguaje natural desde hace 30 años”
Este no es el único caso de hardware infrautilizado. Mi también admiradísimo John Carmack planteaba recientemente otro ejercicio de este tipo:

Como explica Carmack, si se hubiesen hecho algunas modificaciones al ordenador Cray-1 (El primer superordenador del que algún día hablaré) y se hubiese puesto en manos de investigadores como Geoffrey Hinton, podríamos haber adelantado la llegada de la explosión del Machine Learning nadas más y nada menos que dos décadas.

Podríamos haberlo hecho, sí, pero aún no sabíamos como hacerlo. Ahora, la pregunta que se nos plantea es. ¿Qué cosas que podríamos hacer hoy no estamos haciendo con el hardware actual? ¿Qué oportunidades estamos perdiendo? El tiempo nos dirá y, seguramente, nos sorprenderá.
¡Gracias como siempre por leer hasta aquí!
¿Te gusta The Independent Sentinel? ¡Ayúdame a que más gente conozca la publicación!
Si tienes comentarios o quieres iniciar una conversación, recuerda que puedes hacerlo aquí.
Si te has perdido alguna edición de la newsletter o quieres volver a leerlas, puedes acceder a todas aquí.
Si quieres escuchar todas las canciones de The Independent Sentinel, echa un vistazo a esta lista de Spotify.